
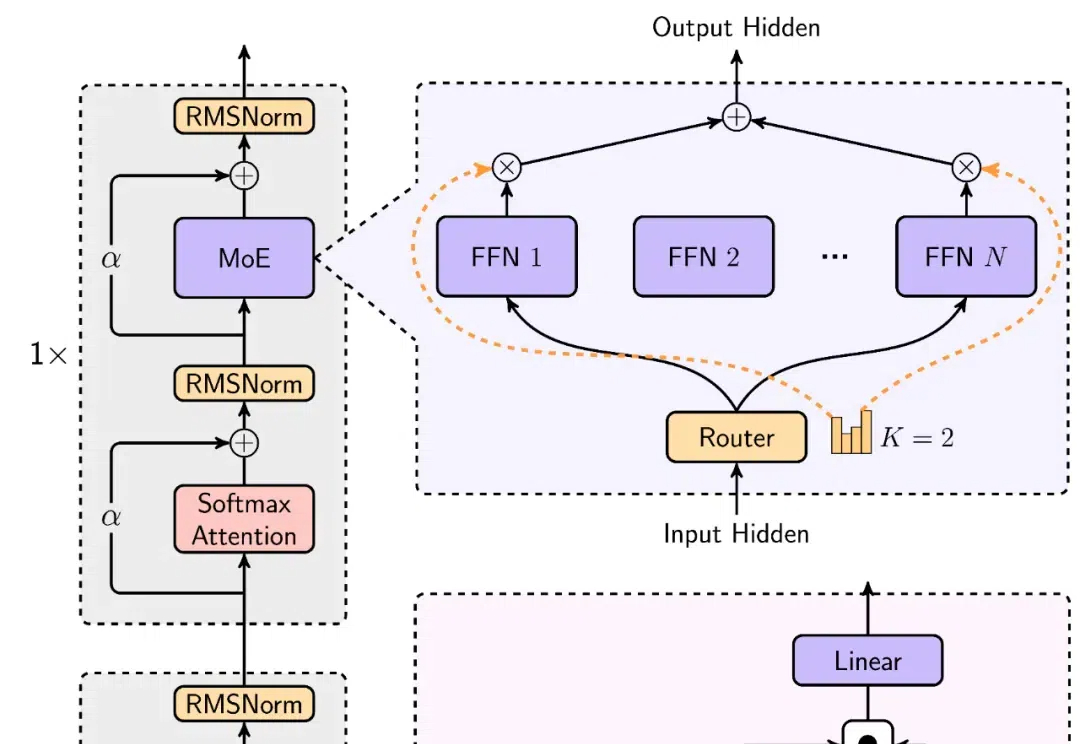
一句话让Agent自主干活,清华复旦斯坦福等开源的智能体开发框架抢先了OpenAI
一句话让Agent自主干活,清华复旦斯坦福等开源的智能体开发框架抢先了OpenAI近期,OpenAI CEO Sam Altman 宣布,2025 年将推出名为 “Operator” 的虚拟员工计划,AI 代理将能够自主执行任务,如写代码、预订旅行等,成为企业中的 “数字同事”。
来自主题: AI技术研报
8946 点击 2025-01-16 10:12
 搜索
搜索
近期,OpenAI CEO Sam Altman 宣布,2025 年将推出名为 “Operator” 的虚拟员工计划,AI 代理将能够自主执行任务,如写代码、预订旅行等,成为企业中的 “数字同事”。
「2025 年,我们可能会看到第一批 AI Agent 加入劳动力大军,并对公司的生产力产生实质性的影响。」——OpenAI CEO Sam Altman
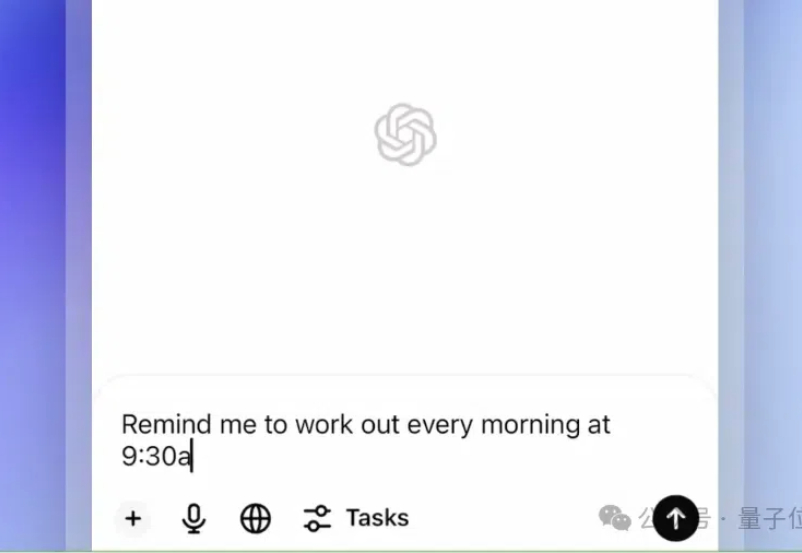
开年第一剑,OpenAI Agent闪亮登场! ChatGPT新功能「Tasks」,让AI有了执行力,可以替你完成各种任务。
去年初,朱啸虎接受了张小珺的采访。 彼时,月之暗面刚刚完成 10 亿美元融资,用户增长数据一路绝尘。OpenAI 发布 Sora 了技术报告和演示视频,整个 AI 圈再次狂欢。

1 月 13 日晚,OpenAI 官方发布了 16 页《OpenAI’s Economic Blueprint》经济蓝图报告,描绘了美国如何最大限度的发挥 AI 优势、加强国家安全以及推动经济增长的政策建议(公众号后台回复【OpenAI】获得完整报告)。
OpenAI 接连发布 o1 和 o3 模型,大模型的高阶推理能力正在迎来爆发式增强。在预训练 Scaling law “撞墙” 的背景下,探寻新的 Scaling law 成为业界关注的热点。高阶推理能力有望开启新的 Scaling law,为大模型的发展注入新的活力。

OpenAI Realtime API 的「说明书」。

大模型长序列的处理能力已越来越重要,像复杂长文本任务、多帧视频理解任务、以及 OpenAI 近期发布的 o1、o3 系列模型的高计算量模式,需要处理的输入 + 输出总 token 数从几万量级上升到了几百万量级。
OpenAI o1 给大模型规模扩展 vs 性能的曲线带来了一次上翘。它在大模型领域重现了当年 AlphaGo 强化学习的成功 —— 给越多算力,就输出越多智能,一直到超越人类水平。
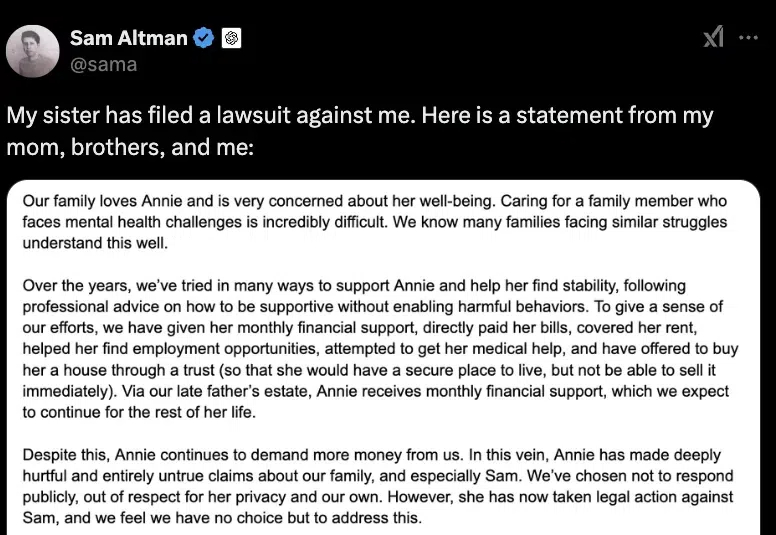
我去,OpenAI CEO奥特曼的亲妹妹,一纸状书,把她亲哥给告了! 想不到让奥特曼再次陷入舆论危机的矛头,这次居然来自家庭内部,来自小他9岁的妹妹安妮·奥特曼(Annie Altman)。